
Last Update:
Asynchronous Tasks with std::future and std::async from C++11
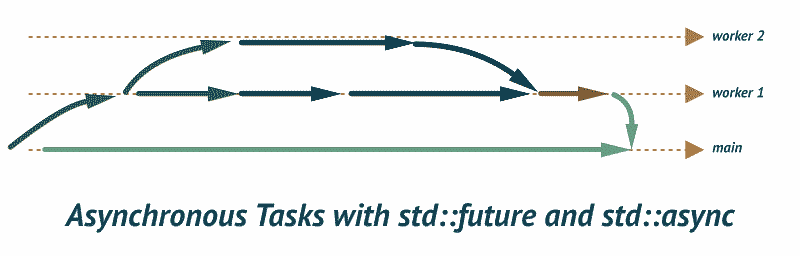
Table of Contents
Let’s consider a simple task: “Use a worker thread to compute a value”.
In the source it can look like the following line:
std::thread t([]() { auto res = perform_long_computation(); };
We have a thread, and it’s ready to start. But how to get the computed value efficiently out of that thread?
Last Update: 8th June 2020
Solutions
Let’s continue with the problem.
The first solution might be to use a shared variable:
MyResult sharedRes;
std::thread t([]() { sharedRes = perform_long_computation(); };
The result of the computation is stored in sharedRes, and all we need to do is to read this shared state.
Unfortunately, the problem is not solved yet. You need to know that the thread t is finished and sharedRes contains a computed value. Moreover, since sharedRes is a global state, you need some synchronization when saving a new value. We can apply several techniques here: mutexes, atomics critical sections…
Maybe there is a better and simpler way of solving our problem?
Have a look below:
auto result = std::async([]() { return perform_long_computation(); });
MyResult finalResult = result.get();
In the above code, you have everything you need: the task is called asynchronously, finalResult contains the computed value. There is no global state. The Standard Library does all the magic!
Isn’t that awesome? But what happened there?
Improvements with Futures
In C++11 in the Standard Library, you have now all sorts of concurrency features. There are common primitives like threads, mutexes, atomics and even more with each of later Standards.
But, the library went even further and contains some higher-level structures. In our example, we used futures and async.
If you do not want to get into much details, all you need to know is that std::future<T> holds a shared state and std::async allows you to run the code asynchronously. We can “expand” auto and rewrite the code into:
std::future<MyResult> result = std::async([]() {
return perform_long_computation();
});
MyResult finalResult = result.get();
The result is not a direct value computed in the thread, but it is some form of a guard that makes sure the value is ready when you call .get() method. All the magic (the synchronization) happens underneath. What’s more the .get() method will block until the result is available (or an exception is thrown).
A Working Example
As a summary here’s an example:
#include <thread>
#include <iostream>
#include <vector>
#include <numeric>
#include <future>
int main() {
std::future<std::vector<int>> iotaFuture = std::async(std::launch::async,
[startArg = 1]() {
std::vector<int> numbers(25);
std::iota(numbers.begin(), numbers.end(), startArg);
std::cout << "calling from: " << std::this_thread::get_id() << " id\n";
std::cout << numbers.data() << '\n';
return numbers;
}
);
auto vec = iotaFuture.get(); // make sure we get the results...
std::cout << vec.data() << '\n';
std::cout << "printing in main (id " << std::this_thread::get_id() << "):\n";
for (auto& num : vec)
std::cout << num << ", ";
std::cout << '\n';
std::future<int> sumFuture = std::async(std::launch::async, [&vec]() {
const auto sum = std::accumulate(vec.begin(), vec.end(), 0);
std::cout << "accumulate in: " << std::this_thread::get_id() << " id\n";
return sum;
});
const auto sum = sumFuture.get();
std::cout << "sum of numbers is: " << sum;
return 0;
}
You can play with the code @Coliru
In the above code, we use two futures: the first one computes iota and creates a vector. And then we have a second future that computes the sum of that vector.
Here’s an output that I got:
calling from: 139700048996096 thread id
0x7f0e6c0008c0
0x7f0e6c0008c0
printing numbers in main (id 139700066928448):
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
accumulate in: 139700048996096 thread id
sum of numbers is: 325
The interesting parts:
- On this machine the runtime library created one worker thread and used it for both futures. There’s the same thread id for the
iotathread and theaccumulatethread. - The vector is created in the
iotathread and then it’s moved tomain()- we can see that the.data()returns the same pointer.
New Possibilities
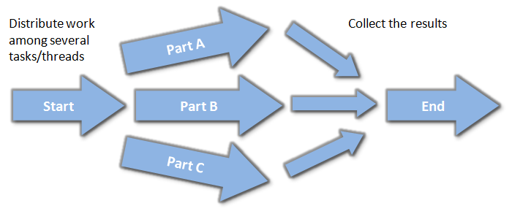
This high-level facilities from C++11 open some exciting possibilities! You can, for instance, play with Task-Based Parallelism. You might now build a pipeline where data flows from one side to the other and in the middle computation can be distributed among several threads.
Below, there is a simple idea of the mentioned approach: you divide your computation into several separate parts, call them asynchronously, and at the end, collect the final result. It is up to the system/library to decide if each piece is called on a dedicated thread (if available), or just run it on only one thread. This makes the solution more scalable.
But… after nine years after the C++11 was shipped… did it work?
Did std::async Fulfilled its Promises?
It seems that over the years std::async/std::future got mixed reputation. It looks like the functionality was a bit too rushed. It works for relatively simple cases but fails with advanced scenarios like:
- continuation - take one future and connect it with some other futures. When one task is done, then the second one can immediately start. In our example, we have two tasks, but there’s no way we can join them without manual orchestration.
- task merging - the C++11 API doesn’t allow to merge and wait for several futures at once.
- no cancellation/joining - there’s no way to cancel a running task
- you don’t know how the tasks will be executed, in a thread pool, all on separate threads, etc.
- it’s not a regular type - you cannot copy it, it’s only move-able type.
- and few other issues.
While the mechanism is probably fine for relatively simple cases, you might struggle with some advanced scenarios. Please let me know in comments about your adventures with std::future.
Have a look at the resource section where you can find a set of useful materials on how to improve the framework. You can also see what the current alternatives are.
You can also have a look at my recent question that I asked on Twitter:
Notes
.get()can be called only once! The second time you will get an exception. If you want to fetch the result from several threads or several times in single thread you can usestd::shared_future.std::asynccan run code in the same thread as the caller. Launch Policy can be used to force truly asynchronous call -std::launch::asyncorstd::launch::deferred(perform lazy call on the same thread).- when there is an exception in the code of the future (inside a lambda or a functor), this exception will be propagated and rethrown in the
.get()method.
References
- See The C++ Standard Library: A Tutorial and Reference (2nd Edition) - chapter 18.1 for a great introduction to the concurrency in
std; - See The C++ Programming Language, 4th Edition
- C++ Concurrency in Action 2nd Edition
On std::future patterns and possible improvements:
- There is a Better Future - Felix Petriconi - code::dive 2018 - YouTube
- code::dive 2016 conference – Sean Parent – Better Code: Concurrency - YouTube
- Core C++ 2019 :: Avi Kivity :: Building efficient I/O intensive applications with Seastar - YouTube
- STLAB: Concurrency
- Home · Stiffstream/sobjectizer Wiki
I've prepared a valuable bonus if you're interested in Modern C++!
Learn all major features of recent C++ Standards!
Check it out here: